

This post is a bit different than usual – I decided to share a few tech details, regarding the scaling of our SECockpit Keyword Tool.
When we first launched SECockpit back in 2010 to a small group of selected users, we had no idea what would happen. SECockpit was running in a shared hosting with a shared database server!
The reaction was more than overwhelming! In the same week we made this small launch, we were forced to migrate SECockpit to a dedicated Server. As we continued with smaller promotions and our user base kept on growing, we realised a single Sever wouldn’t be sufficient for ever. We needed a scalable concept for SECockpit.
Vertical vs. Horizontal Scaling
The first think we had to learn, is that you can’t just add power to a server if you get more traffic. For one thing, there are physical limits, as to how many CPUs you can add, but more importantly you have a single point of failure. If your server is down, the entire application is down.
Vertical Scaling refers to just adding power to one server, Horizontal Scaling splits your load onto multiple servers.
The Magical Word
The answer to all our problems seemed to be this magical word “Cloud”. The concept sounds very promising: you place your application into an environment – eg. Amazon – and the processing power will scale inline to your traffic. That’s what we needed!
However, this concept had a catch for SECockpit. Placing files into a cloud – for examples videos, or PDFs – is very easy. Why? Users can only view the files – they cannot change the data. However, SECockpit users don’t just want to view data – they want to write data too! We currently have a database with around 70 million (!!) rows of data. That’s when we realised, there is no “off the shelf” solution to scale large databases.
There are two different approaches to scaling a database, that we considered:
- Database Cluster
- Master/Slave Replication
Database Cluster
The basic idea of a cluster is you have multiple servers, which synchronise themselves. Users can read and write on every server.
Advantages
- No single point of failure
- Every Server can be used for read and write operations
Disadvantages
- Expensive and complicated setup
- Servers are synchronised with a greater delay than Master/Slave Replication
Master/Slave Replication
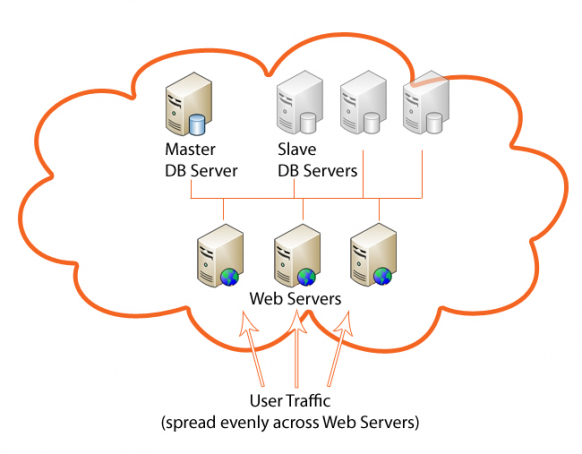
The idea is, you split up reading and writing. You have one master server, where you can write. You can then attach as many slave servers, which replicate themselves automatically from the master. However, you can only read from the slave servers.
Advantages
- Simple setup
- All servers are synchronised with very little delay (max. a few seconds)
- Easier to implement into an application than a cluster
Disadantages
- Single point of failure – if the master is down, no writing anymore
- Master Server can only be scaled vertically
Decision for SECockpit
After a long evaluation phase, we finally decided to go for the Master/Slave Replication. The simple implementation, lower costs and easier maintenance outweigh the disadvantages.
The biggest disadvantage is the single point of failure. However, should the master server crash, users can still use the application. They can “read” everything, but couldn’t, for example, start a new keyword search. We have a backup system in place, which would allow us to restore the entire server under an hour.
Another disadvantage is, that you cannot scale the master server. However, we came to the conclusion, that if we reach the point, where the write operations on the database need more power than a single server can provide, our user base will be so large, that by that time we’d have many other problems :-)
So, that’s a very brief overview of some of the most important decisions we’ve made to the backend of SECockpit. If you have any questions or comments, please join in the discussion below!
I’d be keen to hear if you’d be interested in hearing more tech talk.